
I am currently a Ph.D. student at Shanghai Jiao Tong University (SJTU) under the supervision of Prof. Dahua Lin. I am currently conducting my research at the Shanghai AI Laboratory, where I am jointly advised by Yuhang Zang and Jiaqi Wang. My research focuses on Multimodal Large Language Models, Reinforcement Fine-Tuning and Reinforcement Learning, AI Agent, and Reward Model.
🔥 News
- [2025-12-09] One paper, RAR, is accepted by IEEE Transactions on Image Processing.
- [2025-06-26] One paper, Visual-RFT, is accepted by ICCV 2025.
- [2025-05-14] One paper, InternLM-XComposer2.5-Reward, is accepted by ACL 2025 Finding.
- [2025-01-23] One paper, MIA-DPO, is accepted by ICLR2025.
- [2024-10-24] One paper, “MIA-DPO: Multi-Image Augmented Direct Preference Optimization For Large Vision-Language Models,” has been rated as the Huggingface “#1 Paper of the Day”.
- [2024-09-28] Two papers, MMDU and MMLONGBENCH-DOC(spotlight), are accepted by NeurIPS2024.
- [2024-06-18] One paper, “MMDU: A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs,” has been rated as the Huggingface “#1 Paper of the Day”.
- [2024-06] We are organizing the Visual Perception via Learning in an Open World: The 4th Workshop on Open World Vision and the V3Det Challenge at CVPR 2024.
📝 Selected Publications
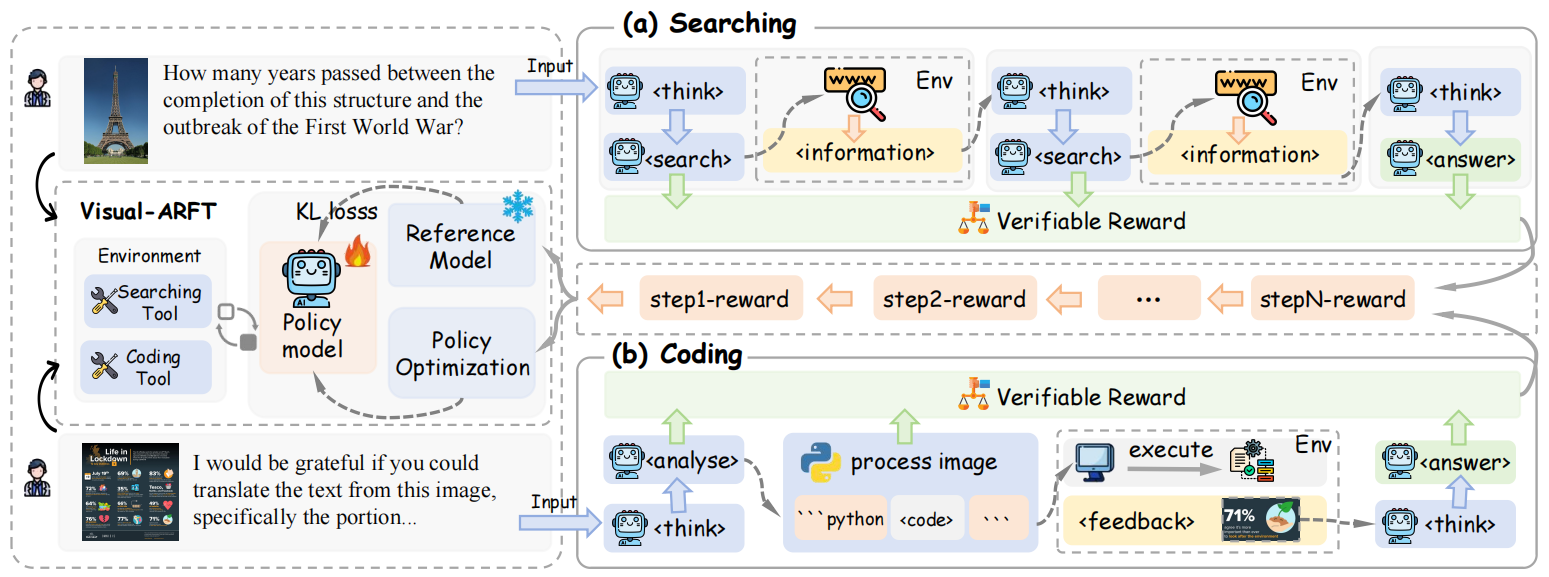
Visual-ARFT: Visual Agentic Reinforcement Fine-Tuning
Ziyu Liu, Yuhang Zang, Yushan Zou, Zijian Liang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, Jiaqi Wang
This work highlights the effectiveness of Visual Agentic Reinforcement Fine-Tuning (Visual-ARFT) for enabling flexible and adaptive reasoning abilities for Large Vision-Language Models (LVLMs). With Visual-ARFT, open-source LVLMs gain the ability to browse websites for real-time information updates and write code to manipulate and analyze input images through cropping, rotation, and other image processing techniques. We also present a Multi-modal Agentic Tool Bench (MAT) with two settings (MAT-Search and MAT-Coding) designed to evaluate LVLMs’ agentic search and coding abilities.

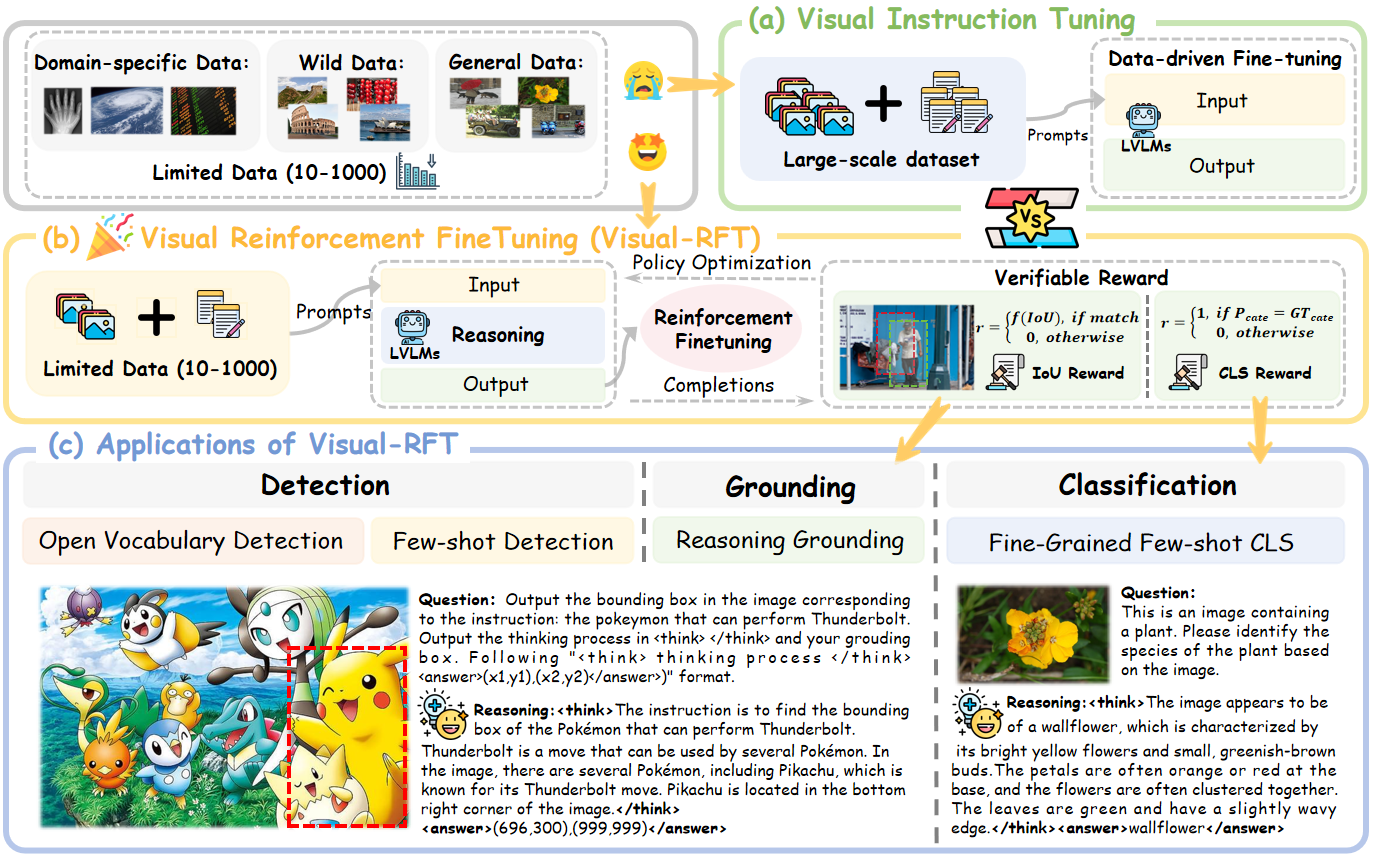
Visual-RFT: Visual Reinforcement Fine-Tuning[Accepted by ICCV2025!]
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, Jiaqi Wang
We introduce Visual Reinforcement Fine-tuning (Visual-RFT), the first comprehensive adaptation of Deepseek-R1’s RL strategy to the multimodal field. We use the Qwen2-VL-2/7B model as our base model and design a rule-based verifiable reward, which is integrated into a GRPO-based reinforcement fine-tuning framework to enhance the performance of LVLMs across various visual perception tasks.
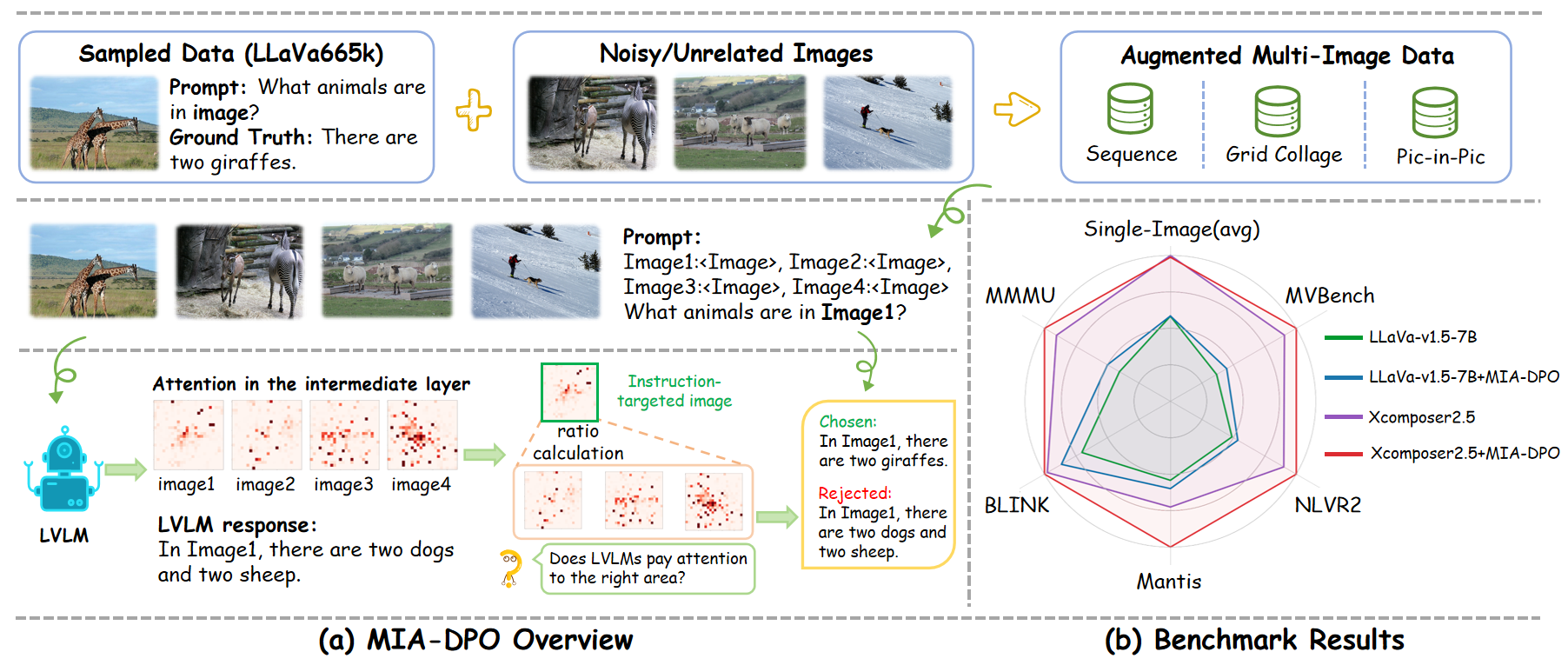
MIA-DPO: Multi-Image Augmented Direct Preference Optimization For Large Vision-Language Models[Accepted by ICLR2025!]
Ziyu Liu, Yuhang Zang, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Haodong Duan, Conghui He, Yuanjun Xiong, Dahua Lin, Jiaqi Wang
We present Multi-Image Augmented Direct Preference Optimization (MIA-DPO), a visual preference alignment approach that effectively handles multi-image inputs. We use attention values to identify and filter out rejected responses the model may have mistakenly focused on…


MMDU: A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs [Accepted by NeurIPS2024!]
Ziyu Liu, Tao Chu, Yuhang Zang, Xilin Wei, Xiaoyi Dong, Pan Zhang, Zijian Liang, Yuanjun Xiong, Yu Qiao, Dahua Lin, Jiaqi Wang
We introduce MMDU, a comprehensive benchmark, and MMDU-45k, a large-scale instruction tuning dataset, designed to evaluate and improve LVLMs’ abilities in multi-turn and multi-image conversations.Our benchmark showcases a conversational setting with a maximum of 20 images and 17 turns. With a maximum of 18k text+image tokens, MMDU evaluates the capacity of LVLMs to process and comprehend extended contextual information with a long context history.

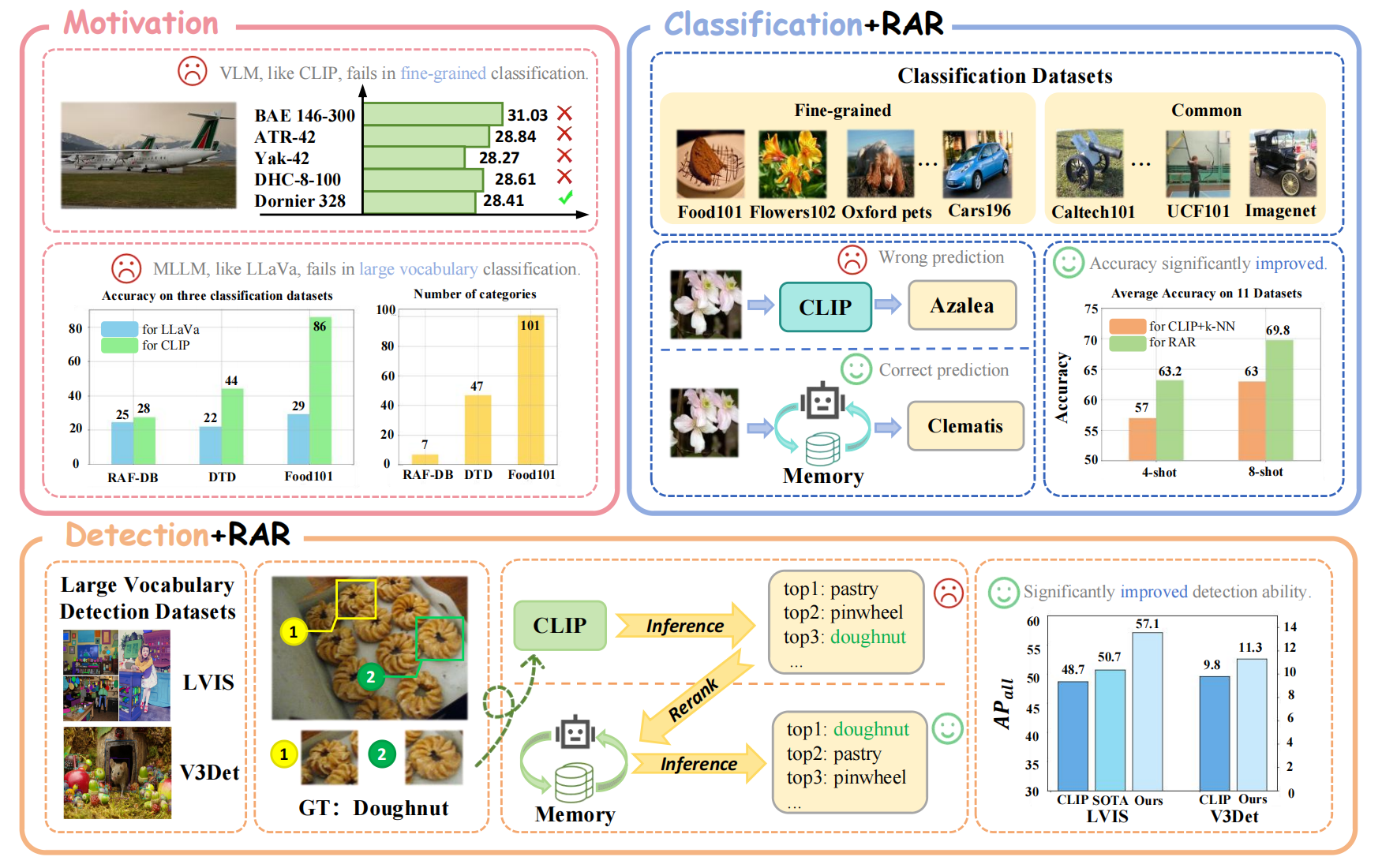
RAR:Retrieving And Ranking Augmented MLLMs for Visual Recognition[Accepted by IEEE Transactions on Image Processing]
Ziyu Liu, Zeyi Sun, Yuhang Zang, Wei Li, Pan Zhang, Xiaoyi Dong, Yuanjun Xiong, Dahua Lin, Jiaqi Wang
Combining retrieving and ranking with multi-modal large language models to revolutionize perception tasks such as fine-grained recognition, zero-shot image recognition, and few-shot object recognition. Our method opens up new avenues for research in augmenting the MLLM’s abilities with the retrieving-augmented solution and could be beneficial for other tasks such as reasoning and generation in future works.

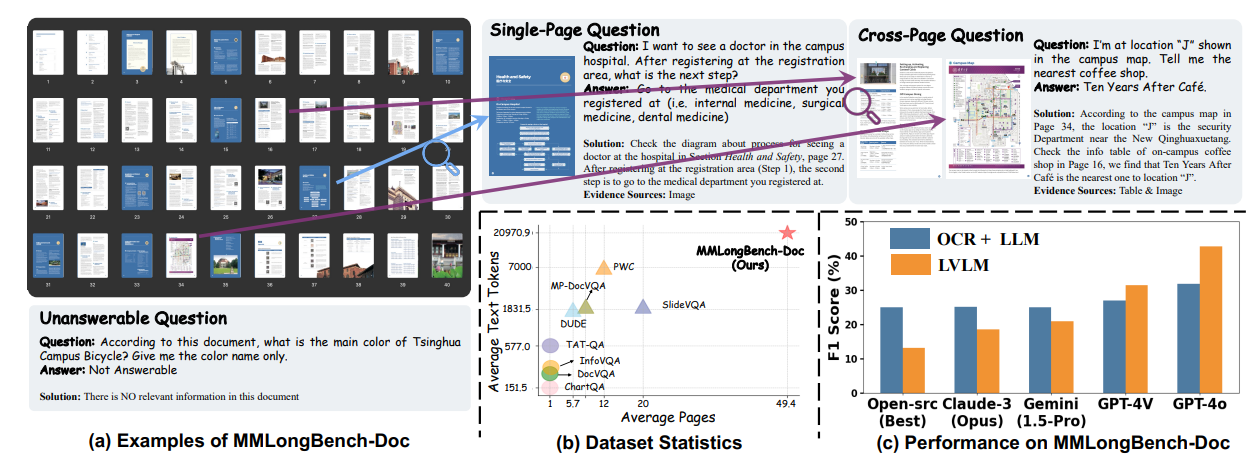
MMLONGBENCH-DOC: Benchmarking Long-context Document Understanding with Visualizations [Accepted by NeurIPS2024!(Spotlight)]
Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, Pan Zhang, Liangming Pan, Yu-Gang Jiang, Jiaqi Wang, Yixin Cao, Aixin Sun

🎖 Honors and Awards
- 2024.06, Excellent Bachelor’s Thesis,Outstanding Undergraduate Graduate.
- 2023.07, Meritorious Award, Mathematical Contest in Modeling and Interdisciplinary Contest in Modeling (MCM/ICM), COMAP.
- 2022.05, National Second Prize, China Undergraduate Mathematical Contest in Modeling(CUMCM), China Society for Industrial and Applied Mathematics(CSIAM).
- 2022.05, Finalist Award, Mathematical Contest in Modeling and Interdisciplinary Contest in Modeling (MCM/ICM), COMAP.
📖 Educations
- 2024.09 - until now, PHD, Shanghai Jiao Tong University.
📌 Activities
- Reviewer of ICLR2025, ICLR2026, Neurips2024, NeurIPS2025 (Top Reviewer), CVPR, TMM.
- Workshop organizing community of VPLOW@CVPR2024